Disclaimer: Saya bukan orang praktisi statistik maupun orang yang memiliki background di bidang statistik. Saya adalah lulusan S1 Teknik Elektro yang pada kurikulumnya hanya mendapatkan mata kuliah “Probabilitas dan Stokastik” di mana topik statistik hanya dibahas oleh dosen pengampu saya dalam 3 kali pertemuan sebagai pengantar sebelum masuk materi kuliah tentang Probability Density Function
Terlalu Panjang; Tidak Membaca (TL;DR): Dugaan pak Ronnie Rusli terhadap kebutuhan sampel yang lebih banyak dari 2000 untuk mencapai margin of error serendah 1% memiliki dasar yang valid berdasarkan teori pengambilan sampel Random Sampling. Metode Stratified Random Sampling dengan 2000 sampel menghasilkan Margin of Error di bawah 1% menurut percobaan dari Penulis. Dengan Margin of Error 1% maupun 2% tetap terdapat jarak lebih besar dari 2 kali Margin of Error untuk kedua metode, sehingga tidak bisa dipungkiri bahwa Quick Count dapat memprediksikan bahwa pasangan ’01’ menang.
Background
Mengapa saya menulis blog post ini? Hal ini saya lakukan karena sebagai alumni Universitas Indonesia, terketuk hati dengan pernyataan pak Ronnie Rusli yang mempertanyakan sampling dari juragan survey Indonesia. Saya dan teman juga skeptis tentang kehebatan juragan survey yang mampu menghasilkan data cukup akurat dengan hanya 2000 data dengan margin of error yang sebesar 1%.
Ramai di jagat media sosial bahwa mereka harus dipertemukan dengan suasana debat akademis. Namun, menurut saya kurang tepat jika hal ini diselesaikan dengan debat akademis, permasalahan ini adalah permasalahan matematika dan dengan mudah dapat diselesaikan dengan perhitungan. Banyak alat yang dapat digunakan pada zaman ini seperti pemrograman Python untuk melakukan simulasi hitungan tanpa perlu menggunakan berlembar-lembar kertas dan pulpen.
Seperti kata banyak orang, “Show, don’t tell“, maka saya akan menunjukkan simulasi perhitungan Quick Count dengan metode Stratified Random Sampling dengan Python. Anda pun dapat mengikuti apa yang saya kerjakan karena saya akan membuka datanya di GitHub saya: https://github.com/josefmtd/kpu-data/
Margin of Error dari Random Sampling
Untuk penjelasan lebih lanjut tentang Margin of Error dan Standard Error, Anda dapat melihat di blog oleh dosen Teknik Industri UI: Bapak Komarudin https://staff.blog.ui.ac.id/komarudin74/mengotak-atik-statistik-quick-count-pilpres-2014/
Seperti dari coretan bapak Ronnie Rusli, margin of error didefinisikan dengan:

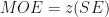
MOE adalah Margin of Error, SD adalah Standard Deviation, n adalah jumlah sample, dan z adalah nilai critical yang diambil dari tabel F(z) sesuai dengan nilai confidence level yang kita inginkan. Untuk confidence level 99%, kita menggunakan nilai z = 2.58.
Untuk mencari sample size dari sebuah data pilihan biner seperti Pemilu yakni antara 01 dan 02, maka dapat digunakan rumus Standard Error khusus untuk proporsi yakni:

dengan menggabungkan rumus di atas dengan rumus MOE dan mengubahnya untuk mencari jumlah sampel (n) maka didapatkan persamaan:

p adalah persentase suara 01 dan (1-p) merepresentasikan suara 02, karena sebelum sampling kita tidak bisa menebak persentase suara, kita dapat masukkan nilai 50% untuk p dan 50% untuk (1-p).


Dengan persamaan ini kita dapat membuktikan secara teori bahwa untuk menghasilkan data dengan Margin of Error sebesar 1% perlu 16641 sampel dan 0.5% perlu 66564 sampel. Sementara Quick Count Indikator dengan sampel 2975 disebut-sebut dapat menghasilkan Margin of Error sebesar 0.63%, dan Quick Count SMRC dengan sampel 5907 TPS dapat menghasilkan Margin of Error sebesar 0.5%. Hal ini tentu berkontradiksi dengan persamaan yang saya tunjukkan di atas. Saya dan teman saya, setuju dengan pak Ronnie Rusli yang skeptis dengan nilai sampel yang sangat sedikit dapat menghasilkan Margin of Error yang sangat rendah.
Namun, perlu digarisbawahi juga sikap skeptis ini berdasarkan teori statistik Random Sampling. Sikap skeptis ini bukan karena pendirian partisan, namun karena dasar ilmiah. Teman sayapun berbicara: “Always question your results“, maka saya mencoba melakukan Random Sampling dengan Python untuk membuktikan apakah benar lembaga survey dapat menghasilkan margin of error serendah itu dengan sampel 2000 TPS?
UPDATE 05 May: Bapak Doktor Ronnie Rusli mengeluarkan rumus yang digunakan untuk mendapatkan sampel:

![\displaystyle n_{tps} = \frac{[p(1-p)]}{\displaystyle \frac{MOE}{z_{99\%}^2} + \frac{p(1-p)}{N}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+n_%7Btps%7D+%3D+%5Cfrac%7B%5Bp%281-p%29%5D%7D%7B%5Cdisplaystyle+%5Cfrac%7BMOE%7D%7Bz_%7B99%5C%25%7D%5E2%7D+%2B+%5Cfrac%7Bp%281-p%29%7D%7BN%7D%7D&bg=ffffff&fg=111111&s=0&c=20201002)

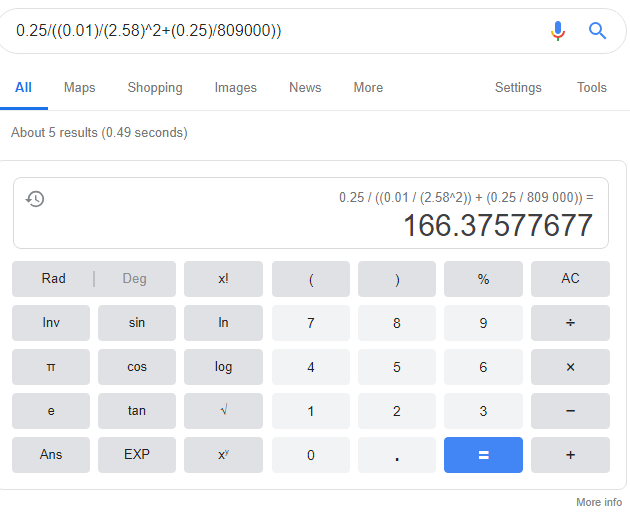
Hasilnya malah melebihi jumlah TPS, sepertinya ada yang salah dengan rumus pak Doktor Ronnie Rusli, saya tetap akan mengambil dari rumus yang saya cantumkan, berasal dari catatan statistik saya dan juga sama dengan yang ditulis oleh bapak dosen Komarudin. Terdapat typo dalam input kalkulator sehingga hasil menjadi salah, persamaan Dr. Ronnie menghasilkan nilai 166 TPS
Menggunakan nilai sampel TPS dengan persamaan oleh Dr. Ronnie, hasilnya adalah 166 TPS, hasil ini malah lebih rendah dari 2000 TPS. Pasti ada kesalahan di persamaan
Intermezzo: Distribusi Suara Nasional
Keskeptisan saya tidak hanya berada pada jumlah sampel, tapi juga terhadap distribusi suara tiap-tiap TPS per provinsi, apakah datanya terdistribusi normal? Seperti yang sudah dibahas di blog bapak dosen FTUI di atas, penggunaan rumus-rumus dalam Quick Count dengan Random Sampling, menggunakan asumsi bahwa data terdistribusi normal, dengan Pilpres yang terlalu terpolarisasi seperti ini, apakah benar Pilpres menghasilkan data distribusi Normal? Saya ragu, sehingga saya mengambil data untuk mencari tahu.
Keraguan saya, saya luapkan dengan code sederhana dalam Python seperti ini (dapat diakses di github.com/josefmtd/kpu-data/distributionPlot.py):
Tekan Spoiler ini untuk menunjukkan code distributionPlot.py
# -*- coding: utf-8 -*-
"""
DistributionPlot.py
Created on Fri May 3 20:35:56 2019
@author: JosefStevanus
"""
import os
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
directory = 'C:/Users/JosefStevanus/Documents/GitHub/kpu-data/'
data = {}
cleanNolSatuNasional = []
cleanNolDuaNasional = []
cleanTotalSuaraNasional = []
for filename in os.listdir(directory):
if filename.endswith(".csv"):
dataName = filename[:-4]
data[dataName] = pd.read_csv(filename)
nolSatu = data[dataName]["01 KPU"]
nolDua = data[dataName]["02 KPU"]
cleanNolSatu = []
cleanNolDua = []
for x in range(len(nolSatu)):
if nolSatu[x] == 0 and nolDua[x] == 0:
continue
else:
cleanNolSatu.append(nolSatu[x])
cleanNolDua.append(nolDua[x])
cleanTotalSuara = np.add(cleanNolSatu, cleanNolDua)
cleanNolSatuNasional += cleanNolSatu
cleanNolDuaNasional += cleanNolDua
cleanTotalSuaraNasional += cleanTotalSuara.tolist()
percentageNolSatu = np.divide(cleanNolSatu, cleanTotalSuara)*100
percentageNolSatuSeries = pd.Series(percentageNolSatu,
name = "Distribusi Persentase Suara 01 di "+dataName )
plotDistribusi, seaborn = plt.subplots()
sns.distplot(percentageNolSatuSeries, kde=False, bins=100, ax=seaborn)
plotDistribusi.savefig('C:/Users/JosefStevanus/Documents/GitHub/kpu-data/'+dataName+".png")
continue
else:
continue
percentageNolSatuNasional = np.divide(cleanNolSatuNasional, cleanTotalSuaraNasional)*100
percentageNolSatuNasionalSeries = pd.Series(percentageNolSatuNasional,
name = "Distribusi Persentase Suara 01 Nasional")
plotDistribusiNasional, seabornNasional = plt.subplots()
sns.distplot(percentageNolSatuNasionalSeries, kde=False, bins=100, ax = seabornNasional)
plotDistribusiNasional.savefig("C:/Users/JosefStevanus/Documents/GitHub/kpu-data/Nasional.png")
Hasilnya saya mendapatkan distribusi suara 01 diseluruh TPS di Indonesia seperti pada Gambar 1. Grafik histogram pada Gambar 1 menunjukkan distribusi yang sama sekali tidak terlihat seperti distribusi normal. Hal ini dapat dimaklumkan karena banyaknya provinsi yang tidak memiliki distribusi normal, contohnya pada Gambar 2 yang menunjukkan distribusi persentase suara di provinsi yang sangat mengunggulkan salah satu pihak (01 atau 02), atau pada Gambar 3 dimana distribusi suara menunjukkan persebaran suara yang terpolarisasi, di mana ada dua nilai peak pada 01 maupun 02.
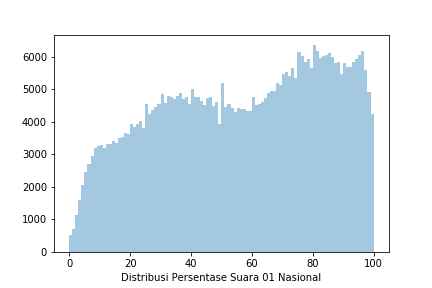
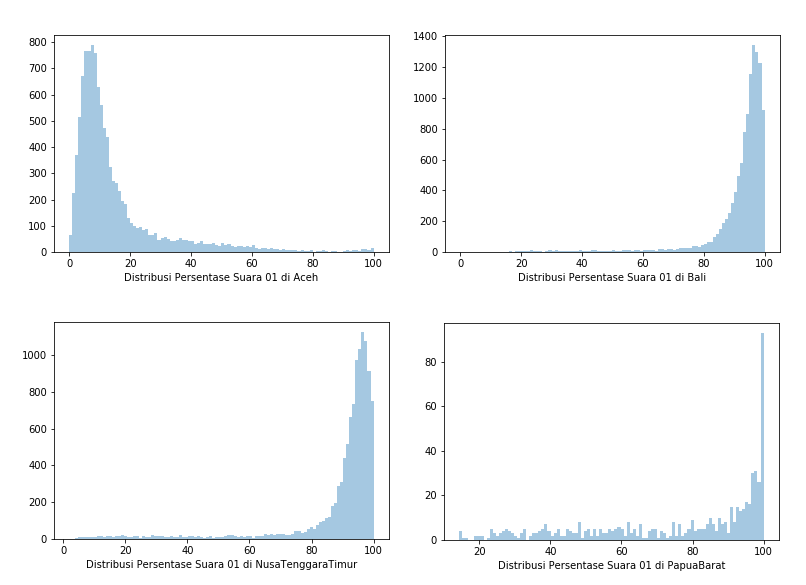
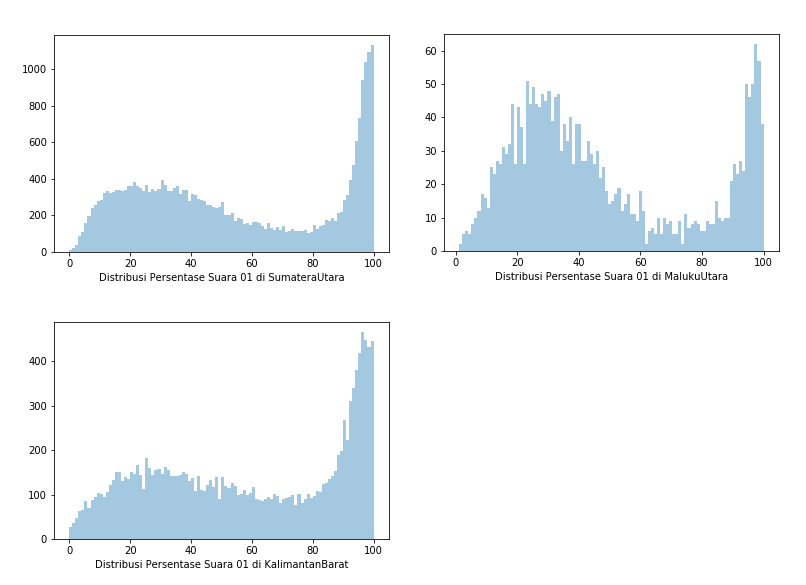
Data yang sangat tidak lazim ini menyebabkan saya semakin skeptis dengan metode Quick Count yang dilaksanakan, karena semakin skeptis, maka saya mulai menulis program singkat dengan Random Sampling dan Stratified Random Sampling.
Random Sampling
Rumus yang saya gunakan di awal adalah rumus untuk mencari jumlah sampel Random Sampling. maka program pertama yang saya buat adalah program Random Sampling menggunakan data sementara dari Situng KPU menggunakan program Python, data saya saya ambil oleh hasil crawling data oleh bapak Yohanda Mandala (https://twitter.com/jokidz90). Data ini terakhir di update oleh beliau pada tanggal 3 Mei jam 08.06 pagi.
Tekan Spoiler ini untuk melihat code RandomSampling.py
# -*- coding: utf-8 -*-
"""
RandomSampling.py
Created on Sat May 4 09:45:12 2019
@author: DarwinHarianto
"""
import os
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import random
directory = 'C:/Users/JosefStevanus/Documents/GitHub/kpu-data/'
data = {}
cleanNolSatuNasional = []
cleanNolDuaNasional = []
cleanTotalSuaraNasional = []
for filename in os.listdir(directory):
if filename.endswith(".csv"):
dataName = filename[:-4]
data[dataName] = pd.read_csv(filename)
nolSatu = data[dataName]["01 KPU"]
nolDua = data[dataName]["02 KPU"]
cleanNolSatu = []
cleanNolDua = []
for x in range(len(nolSatu)):
if nolSatu[x] == 0 and nolDua[x] == 0:
continue
else:
cleanNolSatu.append(nolSatu[x])
cleanNolDua.append(nolDua[x])
cleanTotalSuara = np.add(cleanNolSatu, cleanNolDua)
cleanNolSatuNasional += cleanNolSatu
cleanNolDuaNasional += cleanNolDua
cleanTotalSuaraNasional += cleanTotalSuara.tolist()
continue
else:
continue
percentageNolSatuNasional = np.divide(cleanNolSatuNasional, cleanTotalSuaraNasional)*100
percentageNolSatuNasionalSeries = pd.Series(percentageNolSatuNasional,
name = "Distribusi Persentase Suara 01 Nasional")
plotDistribusiNasional, seabornNasional = plt.subplots()
sns.distplot(percentageNolSatuNasionalSeries, kde=False, bins=100, ax = seabornNasional)
plotDistribusiNasional.savefig("C:/Users/JosefStevanus/Documents/GitHub/kpu-data/Nasional.png")
randomSample = random.sample(range(len(cleanTotalSuaraNasional)), 2000)
nolSatuRandomSample = []
nolDuaRandomSample = []
totalSuaraRandomSample = []
for x in randomSample:
nolSatuRandomSample.append(cleanNolSatuNasional[x])
nolDuaRandomSample.append(cleanNolDuaNasional[x])
totalSuaraRandomSample.append(cleanTotalSuaraNasional[x])
percentageNolSatuRandomSample = np.divide(nolSatuRandomSample, totalSuaraRandomSample)*100
percentageNolSatuRandomSampleSeries = pd.Series(percentageNolSatuRandomSample,
name = "Distribusi Persentase Suara 01 Random Sample")
meanNolSatu = np.sum(nolSatuRandomSample)/np.sum(totalSuaraRandomSample)*100
meanNolDua = 100 - meanNolSatu
standardError = np.std(percentageNolSatuRandomSample)/np.sqrt(len(randomSample))
meanNolSatuNasional = np.sum(cleanNolSatuNasional)/np.sum(cleanTotalSuaraNasional)*100
meanNolDuaNasional = 100 - meanNolSatuNasional
standardErrorNasional = np.std(percentageNolSatuNasional)/np.sqrt(len(cleanTotalSuaraNasional))
plotDistribusiNasionalRandomSample, ax = plt.subplots(2,1)
sns.distplot(percentageNolSatuRandomSampleSeries, kde=False, bins=100, ax = ax[0])
sns.distplot(percentageNolSatuNasionalSeries, kde=False, bins=100, ax = ax[1])
plotDistribusiNasionalRandomSample.suptitle('{:.2f}% vs {:.2f}% Real Count Sementara \n {:.2f}% vs {:.2f}% Random Sampling dengan MOE = +/-{:.2f}%'.format(meanNolSatuNasional, meanNolDuaNasional, meanNolSatu, meanNolDua, standardError*2.58))
plotDistribusiNasionalRandomSample.savefig('RandomSampling.png')
Dalam mengambil sampel random dari Data Seluruh TPS Nasional yang saya dapatkan, saya menggunakan fungsi random yang ada di Python. Saya cukup percaya bahwa komputer tidak memihak 01 maupun 02. Untuk meyakinkan Anda, saya juga menunjukkan distribusi sampel yang diambil oleh program dan dibandingkan dengan distribusi populasi (yakni dari Situng KPU). Selain itu program saya juga menghitung mean persentase 01 dan 02, dan mencari nilai standard error dan margin of error nya. Semua hasil ditunjukkan dalam 1 grafik yang menunjukkan distribusi dan nilai Random Sampling terhadap Real Count.
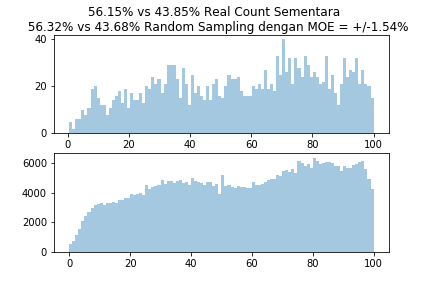
Karena menggunakan Python, saya dapat dengan bebas mengambil beberapa kali Random Sampling sesuka saya, dengan mengambil data yang berbeda-beda. Hasilnya dapat dilihat pada Gambar 5.
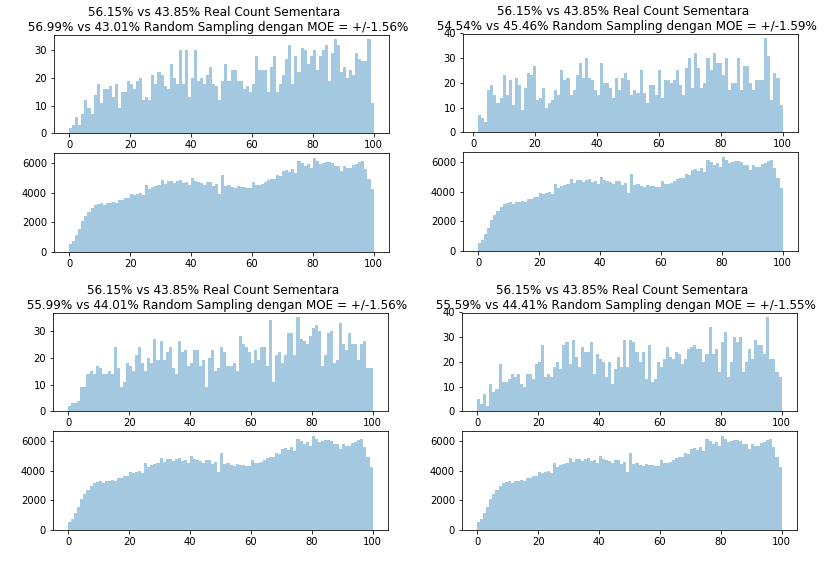
Gambar 5 memperkuat pernyataan bapak Ronnie Rusli bahwa 2000 TPS jelas-jelas tidak cukup untuk menghasilkan Margin of Error dibawah 1.5%, bisa saja saya minta program itu berjalan 1000 kali lagi, saya yakin hasilnya pasti tidak jauh berbeda dari 1.5%.
“Insanity is doing the same thing and expecting a different result”, kata Albert Einstein
Perlu digarisbawahi bahwa Quick Count dari berbagai lembaga survey ini menggunakan Stratified Clustered Random Sampling, di mana suara individu direpresentasikan dalam TPS, dan jumlah TPS yang diambil per provinsi disesuaikan dengan jumlah proporsi penduduknya, sehingga kembali saya mempertanyakan hasil Random Sampling ini dan membuat program Stratified Random Sampling
Stratified Random Sampling
Lembaga survey sudah membagikan laporan quick count mereka, di situ saya dapat melihat berapa jumlah TPS yang mereka pakai, dengan mengikuti proporsi yang mereka gunakan, saya mengambil sampel TPS berdasarkan proporsi jumlah TPS provinsi tersebut dibandingkan TPS seluruh Indonesia.
Mereka menuliskan rumus quick count untuk mendapatkan persentase nilai 01 atau 02 dan juga nilai margin of errornya. Berikut yang ditampilkan oleh lembaga survey tersebut:


Kedua persamaan itu saya realisasikan dalam program Python sebagai berikut:
Tekan Spoiler ini untuk melihat code StratifiedRandomSampling.py
# -*- coding: utf-8 -*-
"""
StratifiedRandomSampling.py
Created on Sat May 4 09:45:12 2019
@author: JosefStevanus
"""
# -*- coding: utf-8 -*-
"""
Created on Fri May 3 20:35:56 2019
@author: JosefStevanus
"""
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import random
class dataPemilu:
def __init__(self, filename, dataSource, totalTPS, sampleSize):
self.totalTPS = totalTPS
self.sampleSize = sampleSize
self.nolSatu = []
self.nolDua = []
self.totalSuara = []
self.sampleNolSatu = []
self.sampleNolDua = []
self.sampleTotalSuara = []
self.nolSatuQuickCount = 0
self.nolDuaQuickCount = 0
self.totalSuaraQuickCount = 0
self.varianceQuickCount = 0
self.filename = filename
self.getRawData(dataSource)
self.cleanData()
self.getQuickCountData()
def getRawData(self, dataSource):
data = pd.read_csv(self.filename)
if dataSource == "KPU":
self.nolSatu = data["01 KPU"]
self.nolDua = data["02 KPU"]
elif dataSource == "KawalPemilu":
self.nolSatu = data ["01 KawalPemilu"]
self.nolDua = data ["02 KawalPemilu"]
else:
print("Source data does not exist")
self.totalSuara = np.add(self.nolSatu, self.nolDua)
def cleanData(self):
cleanNolSatu = []
cleanNolDua = []
for x in range (len(self.totalSuara)):
if self.nolSatu[x] == 0 and self.nolDua[x] == 0:
continue
else:
cleanNolSatu.append(self.nolSatu[x])
cleanNolDua.append(self.nolDua[x])
self.nolSatu = cleanNolSatu
self.nolDua = cleanNolDua
self.totalSuara = np.add(cleanNolSatu, cleanNolDua).tolist()
def randomSample(self):
listSample = random.sample(range(len(self.totalSuara)), self.sampleSize)
for x in listSample:
self.sampleNolSatu.append(self.nolSatu[x])
self.sampleNolDua.append(self.nolDua[x])
self.sampleTotalSuara.append(self.totalSuara[x])
def getQuickCountData(self):
self.randomSample()
self.nolSatuQuickCount = np.sum(self.sampleNolSatu)*self.totalTPS/self.sampleSize
self.nolDuaQuickCount = np.sum(self.sampleNolDua)*self.totalTPS/self.sampleSize
self.totalSuaraQuickCount = np.sum(self.sampleTotalSuara, dtype=np.float64)*self.totalTPS/self.sampleSize # needs 64 bit to prevent overflow
def getVariance(self, proporsi):
vhi = np.subtract(self.sampleNolSatu, np.multiply(proporsi, self.sampleTotalSuara))
vh = np.sum(vhi)/self.sampleSize
variance = np.sum(np.square(vhi-vh))/(self.sampleSize-1)
varianceQuickCount = variance*self.totalTPS*(self.totalTPS-self.sampleSize)/self.sampleSize
return varianceQuickCount
sampleSize = 2000
totalTPSAceh = 17389
totalTPSBali = 12386
totalTPSBanten = 33471
totalTPSBengkulu = 6165
totalTPSDaerahIstimewaYogyakarta = 11781
totalTPSDaerahKhususIbukotaJakarta = 29063
totalTPSGorontalo = 5866
totalTPSJambi = 11342
totalTPSJawaBarat = 70169
totalTPSJawaTengah = 86121
totalTPSJawaTimur = 67454
totalTPSKalimantanBarat = 10791
totalTPSKalimantanSelatan = 6722
totalTPSKalimantanTengah = 4780
totalTPSKalimantanTimur = 6780
totalTPSKalimantanUtara = 1512
totalTPSKepulauanBangka = 3597
totalTPSKepulauanRiau = 4659
totalTPSLampung = 20407
totalTPSMaluku = 2705
totalTPSMalukuUtara = 3805
totalTPSNusaTenggaraBarat = 10082
totalTPSNusaTenggaraTimur = 7656
totalTPSPapua = 1006
totalTPSPapuaBarat = 749
totalTPSRiau = 13174
totalTPSSulawesiBarat = 1857
totalTPSSulawesiSelatan = 14608
totalTPSSulawesiTengah = 3719
totalTPSSulawesiTenggara = 3710
totalTPSSulawesiUtara = 3986
totalTPSSumateraBarat = 13804
totalTPSSumateraSelatan = 19427
totalTPSSumateraUtara = 30883
totalTPSNasional = 809497
aceh = dataPemilu("Aceh.csv", "KPU", totalTPSAceh, int(1.95/100*sampleSize))
bali = dataPemilu("Bali.csv", "KPU", totalTPSBali, int(1.53/100*sampleSize))
banten = dataPemilu("Banten.csv", "KPU", totalTPSBanten, int(4.13/100*sampleSize))
bengkulu = dataPemilu("Bengkulu.csv", "KPU", totalTPSBengkulu, int(0.76/100*sampleSize))
daerahIstimewaYogyakarta = dataPemilu("DaerahIstimewaYogyakarta.csv", "KPU", totalTPSDaerahIstimewaYogyakarta, int(1.46/100*sampleSize))
daerahKhususIbukotaJakarta = dataPemilu("DaerahKhususIbukotaJakarta.csv", "KPU", totalTPSDaerahKhususIbukotaJakarta, int(3.58/100*sampleSize))
gorontalo = dataPemilu("Gorontalo.csv", "KPU", totalTPSGorontalo, int(0.42/100*sampleSize))
jambi = dataPemilu("Jambi.csv", "KPU", totalTPSJambi, int(1.40/100*sampleSize))
jawaBarat = dataPemilu("JawaBarat.csv", "KPU", totalTPSJawaBarat, int(17.05/100*sampleSize))
jawaTengah = dataPemilu("JawaTengah.csv", "KPU", totalTPSJawaTengah, int(14.25/100*sampleSize))
jawaTimur = dataPemilu("JawaTimur.csv", "KPU", totalTPSJawaTimur, int(16.06/100*sampleSize))
kalimantanBarat = dataPemilu("KalimantanBarat.csv", "KPU", totalTPSKalimantanBarat, int(2.04/100*sampleSize))
kalimantanSelatan = dataPemilu("KalimantanSelatan.csv", "KPU", totalTPSKalimantanSelatan, int(1.34/100*sampleSize))
kalimantanTengah = dataPemilu("KalimantanTengah.csv", "KPU", totalTPSKalimantanTengah, int(1.00/100*sampleSize))
kalimantanTimur = dataPemilu("KalimantanTimur.csv", "KPU", totalTPSKalimantanTimur, int(1.34/100*sampleSize))
kalimantanUtara = dataPemilu("KalimantanUtara.csv", "KPU", totalTPSKalimantanUtara, int(0.27/100*sampleSize))
kepulauanBangka = dataPemilu("KepulauanBangka.csv", "KPU", totalTPSKepulauanBangka, int(0.47/100*sampleSize))
kepulauanRiau = dataPemilu("KepulauanRiau.csv", "KPU", totalTPSKepulauanRiau, int(0.67/100*sampleSize))
lampung = dataPemilu("Lampung.csv", "KPU", totalTPSLampung, int(3.24/100*sampleSize))
maluku = dataPemilu("Maluku.csv", "KPU", totalTPSMaluku, int(0.68/100*sampleSize))
malukuUtara = dataPemilu("MalukuUtara.csv", "KPU", totalTPSMalukuUtara, int(0.47/100*sampleSize))
nusaTenggaraBarat = dataPemilu("NusaTenggaraBarat.csv", "KPU", totalTPSNusaTenggaraBarat, int(1.98/100*sampleSize))
nusaTenggaraTimur = dataPemilu("NusaTenggaraTimur.csv", "KPU", totalTPSNusaTenggaraTimur, int(1.85/100*sampleSize))
papua = dataPemilu("Papua.csv", "KPU", totalTPSPapua, int(1.88/100*sampleSize))
papuaBarat = dataPemilu("PapuaBarat.csv", "KPU", totalTPSPapuaBarat, int(0.48/100*sampleSize))
riau = dataPemilu("Riau.csv", "KPU", totalTPSRiau, int(2.18/100*sampleSize))
sulawesiBarat = dataPemilu("SulawesiBarat.csv", "KPU", totalTPSSulawesiBarat, int(0.48/100*sampleSize))
sulawesiSelatan = dataPemilu("SulawesiSelatan.csv", "KPU", totalTPSSulawesiSelatan, int(3.25/100*sampleSize))
sulawesiTengah = dataPemilu("SulawesiTengah.csv", "KPU", totalTPSSulawesiTengah, int(1.13/100*sampleSize))
sulawesiTenggara = dataPemilu("SulawesiTenggara.csv", "KPU", totalTPSSulawesiTenggara, int(0.97/100*sampleSize))
sulawesiUtara = dataPemilu("SulawesiUtara.csv", "KPU", totalTPSSulawesiUtara, int(0.97/100*sampleSize))
sumateraBarat = dataPemilu("SumateraBarat.csv", "KPU", totalTPSSumateraBarat, int(2.06/100*sampleSize))
sumateraSelatan = dataPemilu("SumateraSelatan.csv", "KPU", totalTPSSumateraSelatan, int(3.13/100*sampleSize))
sumateraUtara = dataPemilu("SumateraUtara.csv", "KPU", totalTPSSumateraUtara, int(5.27/100*sampleSize))
## Real Count KPU
nolSatuNasional = aceh.nolSatu + bali.nolSatu + banten.nolSatu + bengkulu.nolSatu + daerahIstimewaYogyakarta.nolSatu + daerahKhususIbukotaJakarta.nolSatu + gorontalo.nolSatu + jambi.nolSatu + jawaBarat.nolSatu + jawaTengah.nolSatu + jawaTimur.nolSatu + kalimantanBarat.nolSatu + kalimantanSelatan.nolSatu + kalimantanTengah.nolSatu + kalimantanTimur.nolSatu + kalimantanUtara.nolSatu + kepulauanBangka.nolSatu + kepulauanRiau.nolSatu + lampung.nolSatu + maluku.nolSatu + malukuUtara.nolSatu + nusaTenggaraBarat.nolSatu + nusaTenggaraTimur.nolSatu + papua.nolSatu + papuaBarat.nolSatu + riau.nolSatu + sulawesiBarat.nolSatu + sulawesiSelatan.nolSatu + sulawesiTengah.nolSatu + sulawesiTenggara.nolSatu + sulawesiUtara.nolSatu + sumateraBarat.nolSatu + sumateraSelatan.nolSatu + sumateraUtara.nolSatu
nolDuaNasional = aceh.nolDua + bali.nolDua + banten.nolDua + bengkulu.nolDua + daerahIstimewaYogyakarta.nolDua + daerahKhususIbukotaJakarta.nolDua + gorontalo.nolDua + jambi.nolDua + jawaBarat.nolDua + jawaTengah.nolDua + jawaTimur.nolDua + kalimantanBarat.nolDua + kalimantanSelatan.nolDua + kalimantanTengah.nolDua + kalimantanTimur.nolDua + kalimantanUtara.nolDua + kepulauanBangka.nolDua + kepulauanRiau.nolDua + lampung.nolDua + maluku.nolDua + malukuUtara.nolDua + nusaTenggaraBarat.nolDua + nusaTenggaraTimur.nolDua + papua.nolDua + papuaBarat.nolDua + riau.nolDua + sulawesiBarat.nolDua + sulawesiSelatan.nolDua + sulawesiTengah.nolDua + sulawesiTenggara.nolDua + sulawesiUtara.nolDua + sumateraBarat.nolDua + sumateraSelatan.nolDua + sumateraUtara.nolDua
totalSuaraNasional = aceh.totalSuara + bali.totalSuara + banten.totalSuara + bengkulu.totalSuara + daerahIstimewaYogyakarta.totalSuara + daerahKhususIbukotaJakarta.totalSuara + gorontalo.totalSuara + jambi.totalSuara + jawaBarat.totalSuara + jawaTengah.totalSuara + jawaTimur.totalSuara + kalimantanBarat.totalSuara + kalimantanSelatan.totalSuara + kalimantanTengah.totalSuara + kalimantanTimur.totalSuara + kalimantanUtara.totalSuara + kepulauanBangka.totalSuara + kepulauanRiau.totalSuara + lampung.totalSuara + maluku.totalSuara + malukuUtara.totalSuara + nusaTenggaraBarat.totalSuara + nusaTenggaraTimur.totalSuara + papua.totalSuara + papuaBarat.totalSuara + riau.totalSuara + sulawesiBarat.totalSuara + sulawesiSelatan.totalSuara + sulawesiTengah.totalSuara + sulawesiTenggara.totalSuara + sulawesiUtara.totalSuara + sumateraBarat.totalSuara + sumateraSelatan.totalSuara + sumateraUtara.totalSuara
persentaseNolSatuNasional = np.divide(nolSatuNasional, totalSuaraNasional)*100
meanNolSatuNasional = np.sum(nolSatuNasional)/np.sum(totalSuaraNasional)*100
meanNolDuaNasional = 100 - meanNolSatuNasional
## Stratified Random Sampling
nolSatuQuickCountNasional = aceh.nolSatuQuickCount + bali.nolSatuQuickCount + banten.nolSatuQuickCount + bengkulu.nolSatuQuickCount + daerahIstimewaYogyakarta.nolSatuQuickCount + daerahKhususIbukotaJakarta.nolSatuQuickCount + gorontalo.nolSatuQuickCount + jambi.nolSatuQuickCount + jawaBarat.nolSatuQuickCount + jawaTengah.nolSatuQuickCount + jawaTimur.nolSatuQuickCount + kalimantanBarat.nolSatuQuickCount + kalimantanSelatan.nolSatuQuickCount + kalimantanTengah.nolSatuQuickCount + kalimantanTimur.nolSatuQuickCount + kalimantanUtara.nolSatuQuickCount + kepulauanBangka.nolSatuQuickCount + kepulauanRiau.nolSatuQuickCount + lampung.nolSatuQuickCount + maluku.nolSatuQuickCount + malukuUtara.nolSatuQuickCount + nusaTenggaraBarat.nolSatuQuickCount + nusaTenggaraTimur.nolSatuQuickCount + papua.nolSatuQuickCount + papuaBarat.nolSatuQuickCount + riau.nolSatuQuickCount + sulawesiBarat.nolSatuQuickCount + sulawesiSelatan.nolSatuQuickCount + sulawesiTengah.nolSatuQuickCount + sulawesiTenggara.nolSatuQuickCount + sulawesiUtara.nolSatuQuickCount + sumateraBarat.nolSatuQuickCount + sumateraSelatan.nolSatuQuickCount + sumateraUtara.nolSatuQuickCount
nolDuaQuickCountNasional = aceh.nolDuaQuickCount + bali.nolDuaQuickCount + banten.nolDuaQuickCount + bengkulu.nolDuaQuickCount + daerahIstimewaYogyakarta.nolDuaQuickCount + daerahKhususIbukotaJakarta.nolDuaQuickCount + gorontalo.nolDuaQuickCount + jambi.nolDuaQuickCount + jawaBarat.nolDuaQuickCount + jawaTengah.nolDuaQuickCount + jawaTimur.nolDuaQuickCount + kalimantanBarat.nolDuaQuickCount + kalimantanSelatan.nolDuaQuickCount + kalimantanTengah.nolDuaQuickCount + kalimantanTimur.nolDuaQuickCount + kalimantanUtara.nolDuaQuickCount + kepulauanBangka.nolDuaQuickCount + kepulauanRiau.nolDuaQuickCount + lampung.nolDuaQuickCount + maluku.nolDuaQuickCount + malukuUtara.nolDuaQuickCount + nusaTenggaraBarat.nolDuaQuickCount + nusaTenggaraTimur.nolDuaQuickCount + papua.nolDuaQuickCount + papuaBarat.nolDuaQuickCount + riau.nolDuaQuickCount + sulawesiBarat.nolDuaQuickCount + sulawesiSelatan.nolDuaQuickCount + sulawesiTengah.nolDuaQuickCount + sulawesiTenggara.nolDuaQuickCount + sulawesiUtara.nolDuaQuickCount + sumateraBarat.nolDuaQuickCount + sumateraSelatan.nolDuaQuickCount + sumateraUtara.nolDuaQuickCount
totalSuaraQuickCountNasional = aceh.totalSuaraQuickCount + bali.totalSuaraQuickCount + banten.totalSuaraQuickCount + bengkulu.totalSuaraQuickCount + daerahIstimewaYogyakarta.totalSuaraQuickCount + daerahKhususIbukotaJakarta.totalSuaraQuickCount + gorontalo.totalSuaraQuickCount + jambi.totalSuaraQuickCount + jawaBarat.totalSuaraQuickCount + jawaTengah.totalSuaraQuickCount + jawaTimur.totalSuaraQuickCount + kalimantanBarat.totalSuaraQuickCount + kalimantanSelatan.totalSuaraQuickCount + kalimantanTengah.totalSuaraQuickCount + kalimantanTimur.totalSuaraQuickCount + kalimantanUtara.totalSuaraQuickCount + kepulauanBangka.totalSuaraQuickCount + kepulauanRiau.totalSuaraQuickCount + lampung.totalSuaraQuickCount + maluku.totalSuaraQuickCount + malukuUtara.totalSuaraQuickCount + nusaTenggaraBarat.totalSuaraQuickCount + nusaTenggaraTimur.totalSuaraQuickCount + papua.totalSuaraQuickCount + papuaBarat.totalSuaraQuickCount + riau.totalSuaraQuickCount + sulawesiBarat.totalSuaraQuickCount + sulawesiSelatan.totalSuaraQuickCount + sulawesiTengah.totalSuaraQuickCount + sulawesiTenggara.totalSuaraQuickCount + sulawesiUtara.totalSuaraQuickCount + sumateraBarat.totalSuaraQuickCount + sumateraSelatan.totalSuaraQuickCount + sumateraUtara.totalSuaraQuickCount
proporsiNolSatu = nolSatuQuickCountNasional/totalSuaraQuickCountNasional
proporsiNolDua = nolDuaQuickCountNasional/totalSuaraQuickCountNasional
persentaseNolSatu = proporsiNolSatu*100
persentaseNolDua = proporsiNolDua*100
print(proporsiNolSatu)
print(proporsiNolDua)
varianceNasional = aceh.getVariance(proporsiNolSatu) + bali.getVariance(proporsiNolSatu) + banten.getVariance(proporsiNolSatu) + bengkulu.getVariance(proporsiNolSatu) + daerahIstimewaYogyakarta.getVariance(proporsiNolSatu) + daerahKhususIbukotaJakarta.getVariance(proporsiNolSatu) + gorontalo.getVariance(proporsiNolSatu) + jambi.getVariance(proporsiNolSatu) + jawaBarat.getVariance(proporsiNolSatu) + jawaTengah.getVariance(proporsiNolSatu) + jawaTimur.getVariance(proporsiNolSatu) + kalimantanBarat.getVariance(proporsiNolSatu) + kalimantanSelatan.getVariance(proporsiNolSatu) + kalimantanTengah.getVariance(proporsiNolSatu) + kalimantanTimur.getVariance(proporsiNolSatu) + kalimantanUtara.getVariance(proporsiNolSatu) + kepulauanBangka.getVariance(proporsiNolSatu) + kepulauanRiau.getVariance(proporsiNolSatu) + lampung.getVariance(proporsiNolSatu) + maluku.getVariance(proporsiNolSatu) + malukuUtara.getVariance(proporsiNolSatu) + nusaTenggaraBarat.getVariance(proporsiNolSatu) + nusaTenggaraTimur.getVariance(proporsiNolSatu) + papua.getVariance(proporsiNolSatu) + papuaBarat.getVariance(proporsiNolSatu) + riau.getVariance(proporsiNolSatu) + sulawesiBarat.getVariance(proporsiNolSatu) + sulawesiSelatan.getVariance(proporsiNolSatu) + sulawesiTengah.getVariance(proporsiNolSatu) + sulawesiTenggara.getVariance(proporsiNolSatu) + sulawesiUtara.getVariance(proporsiNolSatu) + sumateraBarat.getVariance(proporsiNolSatu) + sumateraSelatan.getVariance(proporsiNolSatu) + sumateraUtara.getVariance(proporsiNolSatu)
standardErrorProporsi = np.sqrt(1/np.square(totalSuaraQuickCountNasional)*varianceNasional)
marginOfErrorProporsi = 2*standardErrorProporsi
marginOfErrorPercentage = marginOfErrorProporsi*100
sampleNolSatuNasional = aceh.sampleNolSatu + bali.sampleNolSatu + banten.sampleNolSatu + bengkulu.sampleNolSatu + daerahIstimewaYogyakarta.sampleNolSatu + daerahKhususIbukotaJakarta.sampleNolSatu + gorontalo.sampleNolSatu + jambi.sampleNolSatu + jawaBarat.sampleNolSatu + jawaTengah.sampleNolSatu + jawaTimur.sampleNolSatu + kalimantanBarat.sampleNolSatu + kalimantanSelatan.sampleNolSatu + kalimantanTengah.sampleNolSatu + kalimantanTimur.sampleNolSatu + kalimantanUtara.sampleNolSatu + kepulauanBangka.sampleNolSatu + kepulauanRiau.sampleNolSatu + lampung.sampleNolSatu + maluku.sampleNolSatu + malukuUtara.sampleNolSatu + nusaTenggaraBarat.sampleNolSatu + nusaTenggaraTimur.sampleNolSatu + papua.sampleNolSatu + papuaBarat.sampleNolSatu + riau.sampleNolSatu + sulawesiBarat.sampleNolSatu + sulawesiSelatan.sampleNolSatu + sulawesiTengah.sampleNolSatu + sulawesiTenggara.sampleNolSatu + sulawesiUtara.sampleNolSatu + sumateraBarat.sampleNolSatu + sumateraSelatan.sampleNolSatu + sumateraUtara.sampleNolSatu
sampleNolDuaNasional = aceh.sampleNolDua + bali.sampleNolDua + banten.sampleNolDua + bengkulu.sampleNolDua + daerahIstimewaYogyakarta.sampleNolDua + daerahKhususIbukotaJakarta.sampleNolDua + gorontalo.sampleNolDua + jambi.sampleNolDua + jawaBarat.sampleNolDua + jawaTengah.sampleNolDua + jawaTimur.sampleNolDua + kalimantanBarat.sampleNolDua + kalimantanSelatan.sampleNolDua + kalimantanTengah.sampleNolDua + kalimantanTimur.sampleNolDua + kalimantanUtara.sampleNolDua + kepulauanBangka.sampleNolDua + kepulauanRiau.sampleNolDua + lampung.sampleNolDua + maluku.sampleNolDua + malukuUtara.sampleNolDua + nusaTenggaraBarat.sampleNolDua + nusaTenggaraTimur.sampleNolDua + papua.sampleNolDua + papuaBarat.sampleNolDua + riau.sampleNolDua + sulawesiBarat.sampleNolDua + sulawesiSelatan.sampleNolDua + sulawesiTengah.sampleNolDua + sulawesiTenggara.sampleNolDua + sulawesiUtara.sampleNolDua + sumateraBarat.sampleNolDua + sumateraSelatan.sampleNolDua + sumateraUtara.sampleNolDua
sampleTotalSuaraNasional = aceh.sampleTotalSuara + bali.sampleTotalSuara + banten.sampleTotalSuara + bengkulu.sampleTotalSuara + daerahIstimewaYogyakarta.sampleTotalSuara + daerahKhususIbukotaJakarta.sampleTotalSuara + gorontalo.sampleTotalSuara + jambi.sampleTotalSuara + jawaBarat.sampleTotalSuara + jawaTengah.sampleTotalSuara + jawaTimur.sampleTotalSuara + kalimantanBarat.sampleTotalSuara + kalimantanSelatan.sampleTotalSuara + kalimantanTengah.sampleTotalSuara + kalimantanTimur.sampleTotalSuara + kalimantanUtara.sampleTotalSuara + kepulauanBangka.sampleTotalSuara + kepulauanRiau.sampleTotalSuara + lampung.sampleTotalSuara + maluku.sampleTotalSuara + malukuUtara.sampleTotalSuara + nusaTenggaraBarat.sampleTotalSuara + nusaTenggaraTimur.sampleTotalSuara + papua.sampleTotalSuara + papuaBarat.sampleTotalSuara + riau.sampleTotalSuara + sulawesiBarat.sampleTotalSuara + sulawesiSelatan.sampleTotalSuara + sulawesiTengah.sampleTotalSuara + sulawesiTenggara.sampleTotalSuara + sulawesiUtara.sampleTotalSuara + sumateraBarat.sampleTotalSuara + sumateraSelatan.sampleTotalSuara + sumateraUtara.sampleTotalSuara
persentaseSampleNolSatuNasional = np.divide(sampleNolSatuNasional, sampleTotalSuaraNasional)*100
persentaseSampleNolSatuNasionalSeries = pd.Series(persentaseSampleNolSatuNasional,
name = "Distribusi Persentase Suara 01 Stratified Random Sampling")
plotDistribusiNasionalStratifiedRandomSample, ax = plt.subplots(2,1)
sns.distplot(persentaseNolSatuNasional, kde=False, bins=100, ax = ax[0])
sns.distplot(persentaseSampleNolSatuNasionalSeries, kde=False, bins=100, ax = ax[1])
plotDistribusiNasionalStratifiedRandomSample.suptitle('{:.2f}% vs {:.2f}% Real Count Sementara \n {:.2f}% vs {:.2f}% Stratified Random Sampling dengan MOE = +/-{:.2f}%'.format(meanNolSatuNasional, meanNolDuaNasional, persentaseNolSatu, persentaseNolDua, marginOfErrorPercentage))
plotDistribusiNasionalStratifiedRandomSample.savefig("StratifiedRandomSample4.png")
Program Python ini juga menghasilkan plot distribusi yang membandingkan plot distribusi suara nasional seluruh TPS sementara dengan sampling yang dipakai. Selain itu pada grafik juga dibubuhkan hasil persentase quick count 01 maupun 02 dengan margin of error yang didapatkan dari rumus di atas Gambar 6 menunjukkan hasil stratified random sampling dengan margin of error dibawah 1% dengan jumlah sampel sebesar 2000.
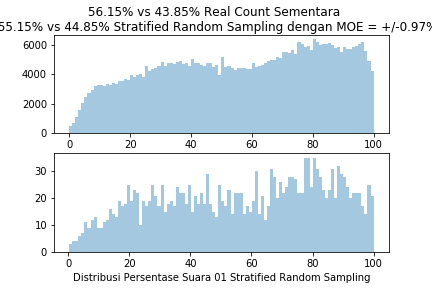
Seperti Random Sampling, saya juga menjalankan program ini 5 kali sehingga terdapat 5 hasil yang berbeda seperti dapat dilihat pada Gambar 7. Gambar 7 menunjukkan dari kelima data yang ditampilkan pada Gambar 6 maupun Gambar 7 memiliki Margin of Error pada sekitaran 0.95%, yakni di bawah 1%. Melihat hasil ini saya dapat memahami bahwa hasil Quick Count dengan 2000 TPS menggunakan metode Stratified Random Sampling itu bukan hal yang mustahil.

Kesimpulan
Menggunakan metode Random Sampling, memang dibuktikan bahwa 2000 TPS tidak akan mencapai Margin of Error sebesar 1%, namun standard Quick Count menggunakan Stratified Random Sampling dan dengan metode ini, percobaan Penulis dalam melaksanakan simulasi Stratified Random Sampling dengan Python membuktikan bahwa Quick Count dari 2000 TPS dapat menghasilkan Margin of Error di bawah 1%
Margin of Error dari Random Sampling memerlukan data yang terdistribusi normal, sedangkan persamaan Margin of Error dari Stratified Random Sampling sudah dengan asumsi bahwa tidak secara persis terdistribusi normal (lihat Metodologi SMRC slide 9). Penggunaan persamaan Margin of Error dengan asumsi distribusi normal terhadap data persebaran suara yang tidak terdistribusi normal, menyebabkan adanya perbedaan pendapat jumlah sampel yang dibutuhkan.
Menggunakan metode Stratified Random Sampling maupun Random Sampling biasa seperti yang ditampilkan di artikel ini, tetap menghasilkan perbedaan suara 01 dan 02 yang cukup signifikan (> 2(moe)) sehingga kesimpulan dari Quick Count tetap sama, yakni pasangan 01 diprediksikan akan memenangi Pemilihan Presiden 2019.
EDITED 05 May: Menambahkan spoiler untuk menunjukkan code, sehingga bagi pembaca yang tidak ingin melihat code dapat melewati bagian code Python yang digunakan.

Penjelasan yang sangat jelas. Terima kasih atas paparannya.
LikeLike
Mencerahkan…
LikeLike
Salah metoda!
Ini penelitian random sampling atau stratified sampling dari sample yg sudah bias, sample yg memenangkan 01 diambil sample lagi untuk pembuktian! Analoginya: ramuan sudah asin, mau dicomot sedikit di sebelah manapun, hasilnya tetep dapet asin.
Setelah membaca source code python nya, tidak ada perhitungan dari persamaan di atas untuk jumlah sample. Jumlah sample di set fixed 2000.
LikeLike
“Saya dan teman juga skeptis tentang kehebatan juragan survey yang mampu menghasilkan data cukup akurat dengan hanya 2000 data dengan margin of error yang sebesar 1%.”
“Seperti kata banyak orang, “Show, don’t tell“, maka saya akan menunjukkan simulasi perhitungan Quick Count dengan metode Stratified Random Sampling dengan Python.”
Saya masukkan nilai 2000 karena skeptis dengan lembaga survey yang bisa hasilkan moe rendah dengan jumlah sampel 2000.
Mengenai masukan pengambilan sampel, saya mengerti dan akan saya coba ikuti masukannya di artikel selanjutnya 🙏
LikeLike
Perlu digarisbawahi bahwa Quick Count dari berbagai lembaga survey ini menggunakan Stratified Clustered Random Sampling, di mana suara individu direpresentasikan dalam TPS, dan jumlah TPS yang diambil per provinsi disesuaikan dengan jumlah proporsi penduduknya, sehingga kembali saya mempertanyakan hasil Random Sampling ini dan membuat program Stratified Random Sampling.
Komentar : Sebenarnya, kata kuncinya sudah Bapak tulis di situ.
Ronnie Rusli, yg bukan orang Statistika, tidak bisa membedakan antara Sampling Unit dan Primary Sampling Unit.
Rekan-rekan yg Lulusan Statistika sekalipun, kalau bukan praktisi QC/Survei Pemilu, banyak terjebak di sini.
Btw, jangan lupa satu hal. Dapat MoE sekian itu, dengan Asumsi seluruh pemilih, menggunakan hak pilihnya. Sehingga, di beberapa lembaga QC, sengaja dilakukan OverSampling.
Terima kasih atas Sharing syntax dan datanya.. Nuhun
LikeLike