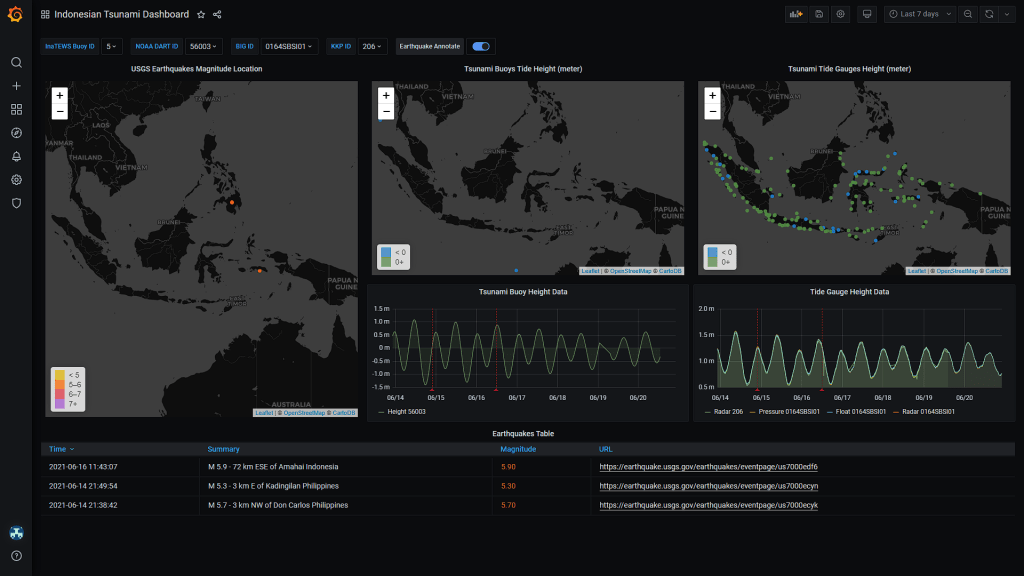
ANSS Comprehensive Earthquake Catalog (ComCat) adalah katalog gempa bumi yang menunjukkan sumber gempa dan produk-produk tambahan lainnya dari jaringan seismik USGS.
USGS juga menyediakan GeoJSON Summary Feed yang diperbaharui setiap 1 menit. GeoJSON adalah format untuk struktur data geografis, dapat merepresentasikan sebuah Geometry, Feature, atau FeatureCollection. GeoJSON dibuat berdasarkan standar JSON.
Saat mengembangkan RECTO Tsunami menggunakan Python, InfluxDB, dan Grafana, saya mengembangkan script sederhana untuk mengunduh data dari USGS. Program ini sekarang sudah saya simpan di PyPI dengan link: https://pypi.org/project/usgs-quake/. Melalui script ini, RECTO Tsunami dapat mengambil data termutakhir dari feed GeoJSON USGS dan menampilkannya ke sebuah dashboard Grafana. Instalasi modul ini dapat dilakukan dengan PIP:
$ pip install usgs-quake
Setelah berhasil instalasi usgs-quake, Anda dapat menggunakan Jupyter Notebook untuk memulai mendapatkan data gempa dalam bentuk pandas.DataFrame seperti contoh di bawah ini.
from usgs_quake import USGSEarthquake
import datetime
# Indonesian boundaries
min_lat = -15
max_lat = 15
min_lon = 90
max_lon = 150
min_mag = 6
# Initializing module with boundaries and minimum magnitude
quakes = USGSEarthquake(min_lat, max_lat, min_lon, max_lon, min_mag)
# Historical Data Query
start = datetime.datetime(1970, 1, 1)
end = datetime.datetime.utcnow()
# Begin querying the ANSS ComCat and get the number of events
count = quakes.get_historical_data(start, end)
df_historical = quakes.get_simplified_dataframe()
# Realtime Data Query
level = 'significant'
period = 'month'
# Query significant earthquakes from the past month
quakes.get_realtime_data(level = level, period = period)
df_realtime = quakes.get_simplified_dataframe()
Semoga artikel singkat ini bermanfaat bagi yang membutuhkan data gempa real-time dari USGS maupun data historis yang tersedia di ComCat.
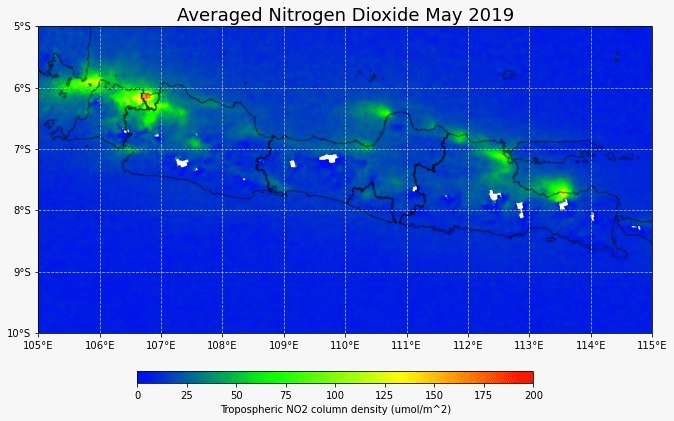
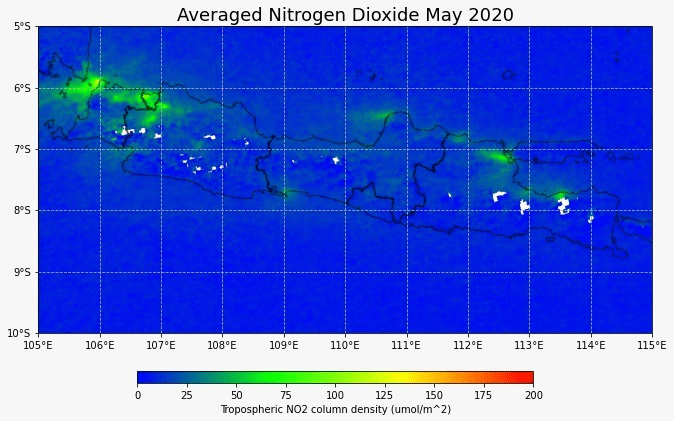
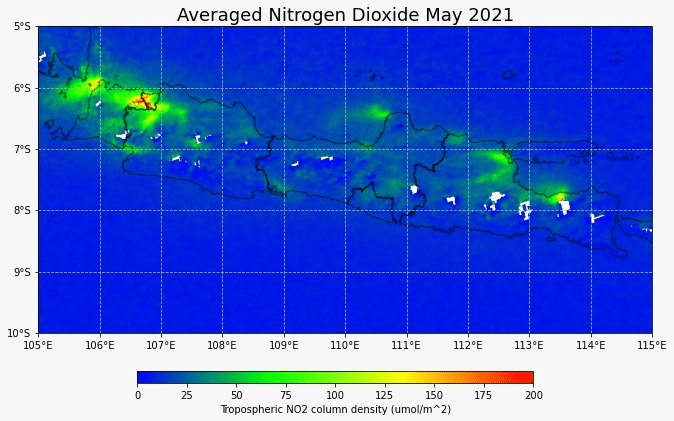
European Space Agency (ESA) beberapa kali telah mengeluarkan peta sebaran konsentrasi gas nitrogen dioksida dan mengorelasikannya dengan aktivitas manusia. Melalui karantina ketat, terlihat dari luar angkasa bahwa emisi gas nitrogen dioksida di suatu wilayah turun dengan signifikan. ESA mengeluarkan gambar yang menunjukkan kurangnya polusi udara sekitar Eropa dan China pada tahu 2020. Menurut peneliti dari KNMI (Royal Netherlands Meteorological Institute), data harian konsentrasi nitrogen dioksida dapat berubah-ubah karena dampak cuaca, namun jika dirata-rata dalam periode waktu tertentu, dampak cuaca ini bisa dihilangkan dan kita dapat melihat efek aktivitas manusia terhadap konsentrasi nitrogen.
Konsentrasi Nitrogen Dioksida di Prancis
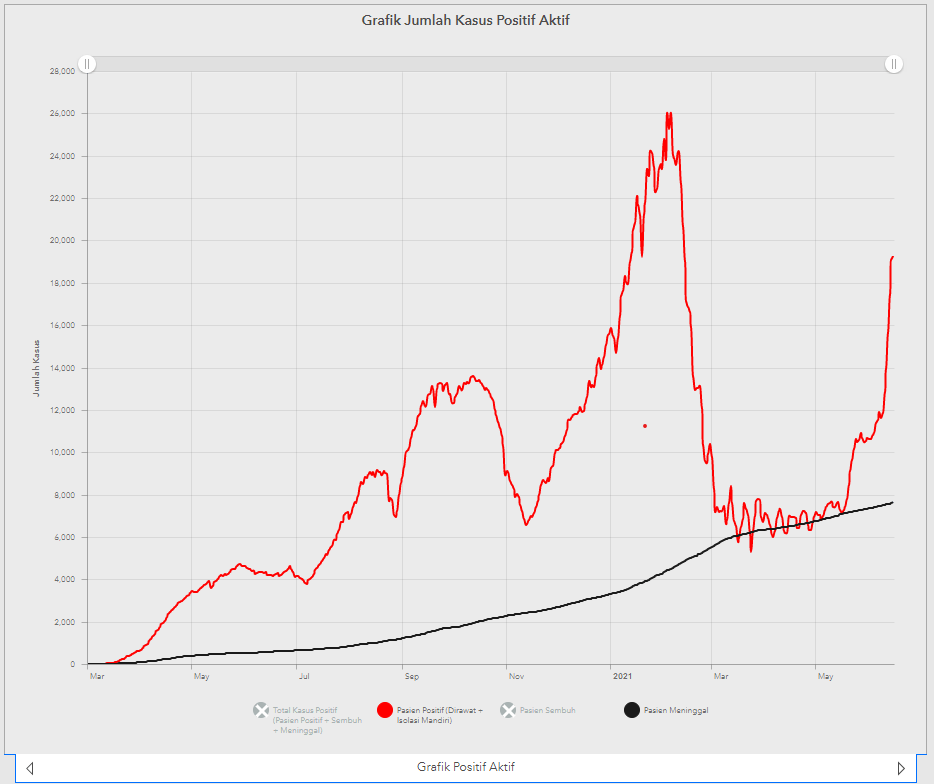
Indonesia sedang mengalami kenaikan kasus COVID-19, dari data Jakarta kita mendapatkan bahwa ada kenaikan yang tajam dari bulan Mei 2021. Data ini dapat diakses di Covid-19 (jakarta.go.id).
Kenaikan Kasus COVID-19 di bulan Mei 2021
Sentinel-5P sebagai satelit terbaik yang dapat memantau konsentrasi nitrogen dioksida berskala global. Kali ini saya coba melakukan visualisasi data bulan Mei 2019, 2020, dan 2021 untuk melihat tren aktivitas manusia berdasarkan data nitrogen dioksida. Terlihat bahwa data nitrogen sudah kembali ke level sebelum pandemi. Aktivitas publik sepertinya sudah kembali ke normal.
Lalu, apa yang bisa dilakukan oleh pemegang kebijakan, apakah membatasi sementara aktivitas dan kembali menerapkan Work From Home bagi industri yang masih sanggup untuk dilakukan dari rumah? Pertanyaan ini mungkin bisa dijawab oleh pemerintah.
Misi satelit Sentinel-5 Precursor, juga dikenal sebagai Sentinel-5P, adalah misi Copernicus pertama yang didedikasikan untuk melakukan pemantauan atmosfer secara global. Satelit ini membawa instrumen TROPOMI (Tropospheric Monitoring Instrument). Instrumen ini dapat memberikan informasi tentang gas nitrogen dioksida (NO2), ozone (O3), formaledehida, sulfur dioksida (SO2), metana (CH4), karbon monoksida (CO), dan aerosol. Polutan gas ini berbahaya bagi kesehatan manusia ataupun berdampak terhadap perubahan iklim.
Instrumen TROPOMI pada misi Sentinel-5P merupakan instrumen paling akurat untuk mengukur polusi udara dari angkasa, melalui kebijakan data terbuka, masyarakat global dapat ikut menggunakan data ini untuk keperluan kebijakan publik tentang perubahan iklim maupun untuk kesehatan masyarakat, serta berbagai aplikasi lainnya.
Kebijakan Data Terbuka
Data terbuka dari Sentinel-5P dapat diakses di SentinelHub, yang dapat diakses dengan link: https://s5phub.copernicus.eu/dhus/#/home. Untuk dapat mengunduh dan melakukan query, perlu login dengan username ‘s5pguest’ dan password ‘s5pguest’. Query dapat dilakukan dengan GUI yang ada di web SentinelHub tersebut. Untuk eksplorasi singkat, GUI ini dapat dipakai untuk mengunduh secara langsung data Sentinel dalam format netCDF.
Google Earth Engine juga memiliki katalog data Sentinel-5P dalam bentuk grid (L3), untuk katalog Near Real-time (NRTI) dan Offline (OFFL), hasil pengolahan dengan harpconvert dari data L2 masing-masing gas hasil olahan data Sentinel-5P yang tersedia di S5PHub. Menggunakan GEE dengan Python API dapat dilakukan pemrosesan dan visualisasi data polutan gas terhadap waktu.
Catatan instalasi dan penggunaan Google Earth Engine API dan Sentinel-5P Hub API untuk mengambil data Sentinel-5P dalam bentuk ee.Image.
Artikel selanjutnya, saya akan mencoba membuat visualisasi polutan gas nitrogen dioksida di atas pulau Jawa sebelum pandemi, saat pandemi, setelah pandemi.
Another article in my “For Dummies” series, without a background in geospatial data and geosciences, this is how I try to make sense of the available geospatial data formats.
GeoTIFF File Format
GeoTIFF is based on the TIFF format and is used as an interchange format for georeferenced raster imagery. The Open Geospatial Consortium (OGC) published version 1.1 of the OGC GeoTIFF Standard in September, 2019.
GeoTIFF file format is in widespread use worldwide and there are strong software support in the form of open source library: libgeotiff and Geospatial Data Abstraction Library (GDAL) package. Specifically the Earth science cloud computing community has developed a means of optimizing GeoTIFF files for use in cloud computing workflows. Cloud Optimized GeoTIFF (COG) files adhere to the GeoTIFF specification so all prior software and workflows can still be used with the COG files.
GeoTIFF format is not suitable for every data type, it is widely used as a distribution format for satellite and aerial photography imagery. GeoTIFF is not suitable for storing complex multi-dimensional data structures nor for storing vector data with many attributes. For these multi-dimensional data, netCDF is widely used within the geospatial data science community and working groups.
Working with Cloud Optimized GeoTIFF in Earth Engine
Earth Engine can load images from Cloud Optimized GeoTIFF (COG) stored in Google Cloud Storage. An example of readily available COG dataset in Google Cloud Storage is the public Landsat dataset. By using Google Cloud Storage, we can store any ee.Image from any Earth Engine operation, but also load COG data hosted on a GCS bucket. In order to utilize this feature, users need to have access to both Google Earth Engine and Google Cloud Platform to create new project and create a Google Cloud Storage within the project to be accessed by the Google user / Service Account.
COG data from external source can also be loaded by Google Earth Engine. As an example, with Python, rio-cogeo library can be used to convert a traditional GeoTIFF to a Cloud Optimized GeoTIFF format, once done, this file can be uploaded to Google Cloud Storage bucket for further analyses in the Google Earth Engine.
I have been working at Nusantara Earth Observation Network for a while, but only exposed to geospatial data recently. Without a formal education on geosciences or geospatial data, I often find myself fumbling for information. One of the most prevalent data format that I come across is netCDF. This article is written as an attempt to rewrite information about netCDF available in the internet from various source.
Network Common Data Form
Network Common Data Form (netCDF) is a file format for storing multidimensional scientific data (variables). Each netCDF file is made up of three basic components: dimensions, variables, and attributes.
A netCDF dimension is used to specify the shape of one or more of the variables, it can be used to represent time, latitude, longitude, or atmospheric level/ocean depth.
A netCDF variable is an array of values on the same type, each variable has a name, data type, and a shape described by a list of dimensions. Scalar variables have empty list of dimensions. A netCDF variable may also have an associated list of attributes to represent information about the variable, such as a units string, valid range of values, special value for missing data, and a long descriptive name.
A netCDF attribute provides auxiliary information about the variables or the dataset itself. With all three components, netCDF is a self-describing file, containing all information describing the data it contains. NetCDF data is machine-independent, by using the eXternal Data Representation (XDR), to represent array of bytes, 16-bit short integers, 32-bit long integers, IEEE-standard 32 and 64 bit floating point numbers. By using this XDR, programs will always deal with integer and floating-point data in the native form of the machine on which they run.
Since netCDF is a self-describing data that is also machine-independent, numerous scientific groups use netCDF to share their data. NetCDF can be accessed by programming interfaces in C, C++, Java, Fortran, Python, IDLL, MATLAB, R, Ruby, and Perl.
Processing NetCDF in Python with Xarray
Xarray expands on the capabilities of NumPy ndarray (N-dimensional array) by addling labels in the form of dimensions, coordinates and attributes on top of NumPy-like arrays. Xarray’s interface is based on the netCDF data model, but it goes beyond the traditional netCDF interfaces. Xarray is designed to be domain agnostic, providing multi-dimensional arrays manipulation for all sorts of applications.
Xarray is tailored to work with netCDF files, which were the source of xarray’s data model, and integrates tightly with dask for parallel computing for large datasets. Xarray has two core data structures, DataArray, which is similar to a pandas.Series for N-dimensional array, and Dataset which is similar to a pandas.DataFrame for a dict-like container of multiple N-dimensional arrays.
Xarray is built on other existing Python libraries, such as NumPy/Pandas for fast arrays/indexing, Dask for parallel computing, matplotlib for plotting.
Anaconda Environment for NetCDF Processing
To begin working with netCDF files on Python, create a new environment, so that your existing environment will be in tact.
Then, we can install from conda-forge channel, the packages we need and a JupyterLab ecosystem to sandbox and work with netCDF data. In this case, rioxarray module is also installed so that netCDF files can be exported as GeoTIFF.
By using rioxarray (rasterio and xarray), we can convert a netCDF file to a raster file (GeoTIFF). An example of how to export netCDF DataArray as a GeoTIFF is as follows:
import xarray as xr
import rioxarray as rxr
fname = 'L3m_20210101-20210108__242278547_4_AV-OLA_ZSD_8D_00.nc'
ds = xr.open_dataset(fname)
ds.rio.set_spatial_dims('lon', 'lat')
ds.rio.set_crs('EPSG:4326')
ds.ZSD_mean.rio.to_raster('ZSD_20210101-20210108_AV-OLA.tif')
Figure 1. Raster data exported from NetCDF, visualized on QGIS
Setelah berhasil menggunakan Google Earth Engine dan Python API, data hasil olahan Anda mungkin ingin ditampilkan di suatu peta untuk dipublikasikan dalam suatu konferensi atau sebagai artikel jurnal. Melalui modul cartoee (cartoee.py) buatan Kel Markert, dan modul geemap (https://geemap.org) buatan Qiusheng Wu, hal ini dapat dilaksanakan dengan bantuan Jupyter Notebook dengan bahasa pemrograman Python.
Format pembuatan gambar ini, layaknya membuat plot dengan library matplotlib.pyplot pada umumnya. Sebelum membuat gambar, pastikan objek Image / Feature yang ingin Anda pasang, untuk contoh kasus kali ini saya menggunakan data cuaca di Sumatera Selatan tanggal 1 Juni 2021. Fungsi yang saya pakai untuk membuat plot tersebut adalah sebagai berikut:
def show_plot(image, vis, bbox, title):
# Create 10 x 12 figure (W x H)
fig = plt.figure(figsize=(12, 10))
# Create colormap
cmap = matplotlib.colors.LinearSegmentedColormap.from_list("",\
["blue","green","yellow","red"])
# Create a map with First Administrative Layer from FAO2015
gaul = ee.FeatureCollection('FAO/GAUL/2015/level1')
ax = cartoee.get_map(gaul, region = bbox)
# Add ee.Image data layer
cartoee.add_layer(ax, image, cmap = cmap,
region = bbox, vis_params = vis)
# Add custom sized colorbar label
cax = ax.figure.add_axes([0.925,0.15,0.02,0.7])
cartoee.add_colorbar(ax = ax, cax = cax,\
vis_params = vis, cmap=cmap)
# Add gridlines to the map
cartoee.add_gridlines(ax, interval=[0.5,0.5], linestyle="--")
# Add a title
ax.set_title(label = title, fontsize=18)
# Show the figure
show()
show_plot(temp, temp_vis_params, bbox, temp_title)
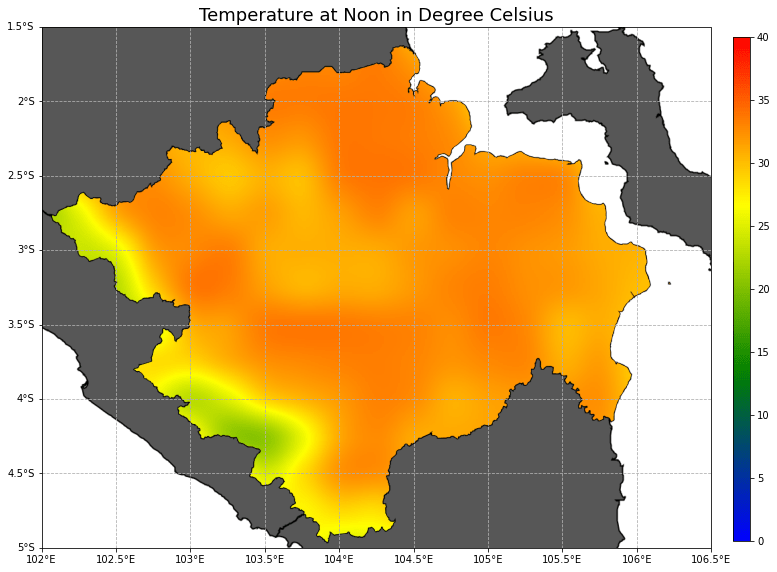
Setelah menggunakan fungsi di atas, akan keluar sebuah gambar di Jupyter Notebook yang dapat diklik kanan dan di simpan sebagai file. Contoh gambarnya dapat dilihat di bawah ini. Menggunakan data raster temperatur, data vektor batas administrasi, kita dapat menunjukkan gambar sederhana yang dapat merepresentasikan sebaran temperatur di sekitar provinsi Sumatera Selatan pada siang hari.
Gambar 1. Temperatur atmosfer di Sumatera Selatan pada tanggal 1 Juni 2021 pukul 12 siang.
Berikut artikel singkat yang membahas pembuatan gambar peta yang terlihat profesional untuk keperluan publikasi ilmiah, untuk contoh-contoh lainnya dan fitur-fitur tambahan yang disediakan geemap dan cartoee, silakan buka web dokumentasi yang telah disediakan.
Sebagai salah satu bagian dari Fire Weather Index (FWI), kode kelembaban dari serasah, atau Fine Fuel Moisture Code (FFMC). Kode ini menunjukkan kemudahan api untuk mulai menyala. Untuk kondisi di Indonesia, FFMC dapat merepresentasikan resiko atau potensi terjadinya api karena kondisi cuaca. Nilai FFMC sangat tergantung terhadap biomassa yang paling umum ditemukan di suatu lokasi. Salah satu cara untuk mengalibrasi kode kelembaban bahan bakar ini adalah dengan melihat kajian historis kejadian kebakaran dibandingkan dengan nilai FFMC pada hari itu.
Kalibrasi dari nilai FFMC yang dilakukan oleh Dymond et al (2005), menggunakan data cuaca dari National Climatic Data Center NOAA untuk tahun 1994 sampai 2001. Akibat keterbatasan data yang tersedia, indeks yang dipakai menggunakan observasi dari nilai mean pada setiap hari, alih-alih dari data pada jam 12 siang hari. Curah hujan selama 24 jam yang dipakai untuk penghitungan indeks, menggunakan data pada 00 UTC, atau jam 7 WIB. Data hotspot yang digunakan berasal dari World Along Track Scanning Radiometer (ATSR).
NASA melalui satelit MODIS memberikan informasi kebakaran melalui Fire Information for Resource Management System (FIRMS). Titik panas yang dideteksi dari luar angkasa ini dapat dipakai untuk melihat data historis titik-titik panas yang disediakan oleh NASA dalam bentuk CSV. Nilai FFMC harian dari tahun 1979 sampai sekarang juga disediakan oleh ECMWF, melalui model ERA5. Melalui dua data ini, bisa dilakukan kembali kalibrasi berdasarkan data-data terkini.
Menggunakan pandas, data CSV hotspot tersebut bisa dipilih berdasarkan tipe kebakaran lahan (vegetation fire) dan dipilih dengan tingkat kepercayaan yang tinggi. Menggunakan xarray, kita dapat mengambil nilai FFMC hasil model dengan resolusi 0.25 x 0.25 derajat, nilai terdekat yang dipilih. Dari penggabungan kedua dataset ini, kita dapat melihat nilai FFMC di hari-hari terjadinya titik panas. Melalui data terbuka dari satelit MODIS dan data ECMWF ini, kalibrasi dapat dilakukan secara regional untuk masing-masing provinsi berdasarkan data historisnya.
Lahan gambut memiliki kemampuan untuk menyimpan banyak karbon, di Indonesia. Lahan gambut tropis sangat berpengaruh terhadap kadar karbon di atmosfer global, ketika terjadi kebakaran hutan, dampaknya sangat buruk terhadap emisi karbon dioksida dan kabut yang dihasilkan dapat mengganggu kesehatan masyarakat. Kebakaran hutan di lahan gambut jarang terjadi secara alami, namun pada kondisi gambut yang kering, mudah terjadi kebakaran. Kabut asap di Indonesia sering sekali terjadi dengan siklus El Nino, kurangnya curah hujan memperburuk musim kemarau pada bulan Mei – September.
Sistem peringkat bahaya kebakaran dapat memberikan informasi pencegahan kebakaran, mobilisasi dan aktivitas pemadaman. Kebakaran hutan dan kabut asap yang terjadi pada tahun 1997-98 menyebabkan perlunya ada peringatan dini melalui adanya sistem peringkat bahaya kebakaran (FDRS). FDRS dapat memberikan informasi dini untuk aktivitas manajemen kebakaran untuk mengurangi perluasan api dan mengurangi dampak kebakaran hutan. Pemerintah Indonesia melalui Badan Pengkajian dan Penerapan Teknologi (BPPT) dengan Canadian Forest Fire Service mengembangkan Fire Danger Rating System (FDRS) yang sekarang sudah operasional di Badan Meteorologi Klimatologi dan Geofisika (BMKG).
Sistem Peringkat Kebakaran Hutan atau Indonesian Fire Danger Rating System menggunakan indeks yang disediakan oleh Canadian Forest Fire Weather Index System (CFFWIS), melalui tiga kode yang menunjukkan kadar kelembaban bahan bakar dan tiga indeks yang menunjukkan sifat api relatif. Untuk menyesuaikan dengan iklim, ketersediaan bahan bakar, dan jenis kebakaran di Indonesia, kalibrasi CFFWIS dilakukan agar representatif dengan kondisi cuaca Indonesia.
Permulaan kejadian kebakaran di suatu waktu sangat terpengaruh oleh kekeringan bahan bakar dan adanya sumber nyala api. Kekeringan relatif dari sampah-sampah berukuran kecil pada sistem CFFWIS didefinisikan sebagai Fine Fuel Moisture Code (FFMC). FFMC dapat digunakan sebagai indikator kemudahan nyala api, kalibrasi FFMC di Indonesia dilakukan melalui pendekatan langsung dan tak langsung, yaitu menggunakan uji pembakaran pada kondisi cuaca yang berbeda dan kajian historis terhadap kejadian kebakaran hutan.
Kabut asap seringkali disebabkan oleh kebakaran lahan gambut. Kebakaran lahan gambut diperkirakan menghasilkan 94% dari keseluruhan emisi PM10 pada saat bencana kabut asap 1997. Kekeringan pada lapisan organik dalam seperti gambut dapat mengindikasikan potensi kebakaran lahan gambut. Pada sistem CFFWIS, Drought Code (DC) dapat dipakai sebagai indikator kekeringan lahan gambut sehingga menjadi indikator potensi terjadinya emisi skala besar. Kalibrasi dari DC dilakukan dengan membandingkan data visibilitas di bandar udara dengan nilai DC.
Komponen Fire Weather Index (FWI) pada CFFWIS dikalibrasikan berdasarkan beban kebakaran. Beban kebakaran didefinisikan sebagai jumlah dan kekuatan dari semua api yang membutuhkan aksi pemadaman pada suatu waktu di area tertentu. Untuk kasus kebakaran akibat rerumputan, Initial Spread Index (ISI) dapat digunakan sebagai estimasi intensitas kebakaran. Komponen ISI pada CFFWIS dikalibrasikan berdasarkan kesulitan pengendalian kebakaran lahan rumput menggunakan Fire Behaviour Prediction dan parameter bahan bakar standar untuk daerah Asia Tenggara.
Duff Moisture Code (DMC) dan Drought Code (DC) juga dikalibrasi untuk daerah khatulistiwa dengan mengatur waktu siang hari (dalam jam) dan faktor pengeringan yang dipakai pada persamaan DMC dan DC. Hasil kalibrasi dari Indonesian Fire Danger Rating System sekarang dipakai untuk komputasi operasional oleh BMKG menggunakan data-data dari jaringan stasiun cuaca BMKG.
Klasifikasi
FFMC
DMC
DC
BUI
ISI
FWI
Rendah
< 72
< 4
< 140
< 6
< 1
< 1
Sedang
73 – 77
5 – 14
140 – 260
7 – 19
2 – 3
1 – 6
Tinggi
78 – 82
15 – 29
260 – 350
20 – 33
4 – 5
6 – 13
Ekstrim
> 82
> 29
> 350
> 33
> 5
> 13
Tabel 1. Hasil kalibrasi Indonesian Fire Weather Index
Sumber
de Groot, W.J., R.D. Field, M.A. Brady, O. Roswintiarti, and M. Mohamad. Development of the Indonesian and Malaysian Fire Danger Rating Systems. Mitigation and Adaptation Strategies for Global Change, 12, 165-180, 2007. [PDF]
Dymond, C.C., R.D. Field, O. Roswintiarti, and Guswanto. Calibrating components of a fire management system using satellite fire detection. Environmental Management, 35, 426-440, 2005. [PDF]
Presipitasi adalah bagian dari siklus air. Presipitasi adalah produk dari kondensasi uap cairan di atmosfer dalam rupa hujan, hujan beku, salju, atau hujan es. Hujan terjadi akibat adanya droplet air berukuran kecil yang terkondensasi bersama partikel debu, garam, atau asap yang berfungsi sebagai nukleus. Setelah kondensasi tambahan, droplet air ini dapat bertumbuh besar ketika partikel-partikel ini bertumbukan. Setelah tumbukan terjadi sehingga droplet memiliki kecepatan jatuh yang mencukupi, maka droplet tersebut akan turun sebagai presipitasi.
Presipitasi digambarkan sebagai kedalaman vertikal yang akan dibentuk oleh air jika berada pada area datar tertentu, jika keseluruhan air yang turun jatuh pada area tersebut. Dewasa ini, peneliti dan ilmuwan dapat menghitung presipitasi secara langsung maupun tidak langsung, menggunakan penakar curah hujan ataupun teknik penginderaan jauh lainnya, seperti menggunakan sistem radar atau satelit.
Pengukuran dari Darat
Penakar hujan (rain gauge) mengukur jumlah curah hujan di lokasi tertentu. Umumnya pengukuran dari masing-masing penakar hujan digunakan untuk merepresentasikan curah hujan di area yang lebih luas, di antara situs penakar hujan berbeda. Namun, kenyataannya curah hujan dapat lebih deras/ringan di lokasi pemasangan penakar hujan atau bahkan tidak ada hujan sama sekali. Kerusakan dan penghalang, maupun adanya angin yang kencang dapat mengganggu pembacaan data curah hujan.
Radar cuaca mulai dikembangkan sejak Perang Dunia ke-II, umumnya digunakan untuk mengukur curah hujan, umumnya di atas daratan. Radar cuaca yang dipasang di darat mengirimkan energi microwave dalam bentuk pulsa dengan lebar beam yang sempit dan melakukan pembacaan dengan pola melingkar. Saat gelombang microwave yang dipancarkan bertemu dengan partikel presipitasi di atmosfer, energi gelombang tersebut akan dipantulkan ke segala arah, beberapa akan kembali ke radar. Pengukuran dengan radar cuaca digunakan untuk melakukan estimasi intensitas, ketinggian, dan jenis presipitasi (hujan, salju, hujan es), dan pergerakannya.
Pengukuran dari Luar Angkasa
Satelit pemantauan bumi dapat memberikan estimasi presipitasi dalam skala global. Untuk menyediakan fitur ini, satelit membawa instrumen pengukuran karakteristik atmosfer seperti temperatur awan dan partikel presipitasi atau hydrometeor. Data ini sangat bermanfaat untuk memberikan perspektif baru di mana data dari darat melalui radar ataupun penakar hujan memiliki keterbatasan. Satelit memberikan persepsi top-down dari turunnya presipitasi, bahkan dapat memberikan struktur tiga dimensi dari presipitasi. Observasi satelit yang demikian dapat dipakai oleh ilmuwan dan peneliti untuk membedakan hujan, salju, dan jenis presipitasi yang lain, serta intensitas struktur dan dinamika dari badai.
Tropical Rainfall Measurement Mission (TRMM) adalah misi gabungan antara NASA dan Japan Aerospace Exploration Agency (JAXA) yang diluncurkan pada tahun 1997. TRMM mengukur hujan deras dan moderat di atas daerah tropis dan subtropis selama 17 tahun, hingga akhir misi tersebut pada April 2015. Pengukuran dari TRMM memberikan pengetahuan tentang fenomena hujan di daerah tropis, terutama di samudera, memberikan gambaran tiga dimensi intensitas badai dan strukturnya dari luar angkasa.
Global Precipitation Measurement adalah misi lanjutan dari TRMM, merupakan misi gabungan NASA-JAXA, berhasil di luncurkan pada tanggal 28 Februari 2014 dari Tanegashima Space Center di Jepang. Sistem ini membawa dua instrumen, Dual-frequency Precipitation Radar (DPR) dan GPM Microwave Imager (GMI). Data yang dihasilkan dari kedua instrmen ini dapat membantu melihat hujan ringan sampai deras dan salju layaknya sebuah CAT scan. Melalui konstelasi satelit internasional yang mengirimkan data presipitasi dari luar angkasa secara global yang dinamakan misi GPM, data hujan dan presipitasi lain seluruh dunia dapat diakses setiap 3 jam.
Algoritma Pengolahan Data Satelit Global Precipitation Measurement
JAXA melalui JAXA Global Rainfall Watch System menyediakan data Global Satellite Mapping of Precipitation (GSMaP) yang menggunakan konstelasi satelit misi GPM dan satelit geostasioner lainnya untuk menghasilkan peta presipitasi global beresolusi tinggi. Data tiap jam dari presipitasi ini dapat diakses dengan resolusi spasial 0.1 derajat x 0.1 derajat. Informasi dari GSMaP digunakan tidak hanya untuk keperluan ilmiah, tapi juga untuk meteorology, pencegahan bencana alam, pemantauan iklim, pemantauan agrikultur, dan lain lain. Penggunaan data GSMaP harus menyantumkan pemilik data yaitu JAXA Global Rainfall Watch System.
NASA juga mengembangkan algoritma IMERG yang menggunakan konstelasi satelit GPM. Algoritma ini juga dapat digunakan untuk mendapatkan angka presipitasi di mana tidak terdapat instrumen di darat. Algoritma ini menggunakan estimasi presipitasi dari waktu operasional TRMM dan digabung dengan estimasi yang didapatkan oleh satelit GPM (2014 – sekarang). Google Earth Engine menyediakan baik algoritma GSMaP maupun IMERG, penggunaan data GSMaP di GEE tetap perlu menyantumkan pemilik data, yaitu JAXA, sedangkan data IMERG merupakan data NASA dan bebas digunakan oleh siapapun.
Gambar 1. Curah hujan kumulatif 24 jam dari GSMaP tanggal 17 Mei 2021 pukul 12.00 WIB (Data: Japan Aerospace Exploration Agency (JAXA))
Peringkat Bahaya Kebakaran adalah komponen dari sistem manajemen kebakaran yang menghitung faktor-faktor bahaya kebakaran menjadi satu atau lebih indeks kualitatif tentang kebutuhan proteksi terkini. Pada praktiknya, bahaya kebakaran dipengaruhi oleh topografi, jenis bahan bakar, dan cuaca. Sistem Pemeringkatan Bahaya Kebakaran di dunia umumnya menggunakan indeks cuaca kebakaran (Fire Weather Index). Canadian Fire Weather IndexSystem (Sistem FWI) menggunakan data cuaca untuk menghitung potensi kebakaran hutan di Kanada. Sistem ini menghitung bahaya kebakaran berdasarkan kondisi lampau dan kondisi sekarang, melalui temperatur, kelembaban, kecepatan angin, dan hujan. Sistem ini mampu menghasilkan informasi yang memadai dengan jumlah data yang sedikit, sehingga sistem ini paling banyak digunakan di dunia.
Van Wagner mengembangkan versi Sistem FWI yang ditulis dalam program FORTRAN 77. Canadian Forecast Service juga menyediakan script untuk menghitung nilai FWI dalam bahasa FORTRAN 95, C, C++, Python, Java, dan SAS/IML. Sistem FWI hanya tergantung oleh pengukuran cuaca yang diambil setiap hari pada tengah hari waktu lokal. Input harian dari sistem terdiri dari temperatur, kelembaban relatif, keepatan angin, dan hujan di atas 24 jam. Melalui data-data ini, FWI menghasilkan tiga kode kelembaban, yaitu:
Fine Fuel Moisture Code (FFMC)
Duff Moisture Code (DMC)
Drought Code (DC)
Nilai kode kelembaban ini jika semakin tinggi, menunjukkan bahaya kebakaran yang lebih tinggi. Sistem FWI juga menghasilkan tiga indeks keluaran, yaitu:
Initial Spread Index (ISI)
Build-Up Index (BUI)
Fire Weather Index (FWI)
Sistem Pemeringkatan Bahaya Kebakaran Indonesia dan Malaysia
Sistem Pemeringkatan Bahaya Kebakaran yang dikembangkan di Indonesia dan Malaysia menggunakan basis yang sama dari Sistem FWI. Perbedaan dari implementasinya adalah bagaimana angka FWI dikalibrasi untuk mengikuti kondisi regional. Umumnya persamaan yang digunakan oleh berbagai negara untuk menghitung nilai FWI tetap sama, namun cara intrepretasi dan kebijakan apa yang ditempuh untuk nilai-nilai yang berbeda. Gambut dan alang-alang umum terjadi di Indonesia, di mana kebakaran gambut umumnya terjadi di bawah tanah dan sulit dipadamkan, dan kebakaran pada alang-alang mudah menjalar ke area yang lebih luas. Kebakaran ini menghasilkan kabut asap yang mengganggu tidak hanya daerah sekitar, namun seringkali sampai negara tetangga.
Umumnya nilai FWI dihitung menggunakan data-datanya dari stasiun cuaca BMKG yang tersebar di sekitar Indonesia, ditambah dengan data-data dari berbagai satelit cuaca. Melalui Google Earth Engine, data cuaca hasil analisis ulang seperti ERA5 Reanalysis dari ECMWF dapat memberikan kondisi perjam dari cuaca dunia dengan resolusi yang tinggi. Data ini dapat digunakan, misalnya untuk menghitung nilai FWI di lahan gambut di Indonesia pada kondisi El Nino lampau, di mana terjadi kekeringan dan kebakaran hutan melanda Indonesia sehingga kabut asap meliputi berbagai daerah. Data ini dapat digabungkan dengan data MODIS untuk melihat kejadian kebakaran hutan. Melalui data-data ini, kita dapat melihat gambaran bagaimana kebakaran terjadi, hanya melalui data MODIS dan FWI.
Artikel ini ditulis dalam rangka merangkum salah satu bahasan di pelatihan sesi pertama oleh NASA (Applied Remote Sensing Training). Program ini berjalan dari 11 Mei 2021 sampai dengan 27 Mei 2021.